SQLModel を使用したテーブル作成 - エンジンを使用する¶
では、コードを見ていきましょう。👩💻
プロジェクトディレクトリ内にいて、仮想環境がアクティブになっていることを確認してください(前の章で説明されているとおり)。
私たちは
- **SQLModel**を使用してテーブルを定義します
- **SQLModel**を使用して同じSQLiteデータベースとテーブルを作成します
- **DB Browser for SQLite**を使用して操作を確認します
こちらが、作成したいテーブル構造のリマインダーです
| id | name | secret_name | age |
|---|---|---|---|
| 1 | Deadpond | Dive Wilson | null |
| 2 | Spider-Boy | Pedro Parqueador | null |
| 3 | Rusty-Man | Tommy Sharp | 48 |
テーブルモデルクラスの作成¶
まず最初に、テーブル内のデータを表現するクラスを作成する必要があります。
データを表すこのようなクラスは、一般的に**モデル**と呼ばれます。
ヒント
このパッケージがSQLModelと呼ばれる理由は、主に**SQLモデル**を作成するために使用されるためです。
そのため、SQLModel(および使用するその他の要素)をインポートし、SQLModelを継承するHeroクラスを作成して、ヒーローの**テーブルモデル**を表します。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
このHeroクラスは、ヒーローの**テーブルを表し**ます。後で作成する各インスタンスは、テーブルの**行を表し**ます。
table=True構成を使用して、これが**テーブルモデル**であり、テーブルを表すことを**SQLModel**に伝えます。
情報
table=Trueを持たないモデルも可能です。それらはデータベースにテーブルを持たない**データモデル**のみであり、**テーブルモデル**ではありません。
これらの**データモデル**は**後で非常に役立ちますが**、今はtable=True構成を追加し続けます。
フィールドとカラムの定義¶
次のステップは、標準的なPython型アノテーションを使用して、クラスのフィールドまたはカラムを定義することです。
これらの変数の名前は、テーブル内のカラム名になります。
そして、それぞれの型はテーブルカラムの型にもなります。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
これらのフィールド/カラム宣言をさらに詳しく見ていきましょう。
オプションフィールドとNULL許容カラム¶
ageから始めましょう。型がOptional[int]であることに注意してください。
そして、標準モジュールtypingからOptionalをインポートします。
これは、「Pythonで何かが 'intまたはNoneの可能性がある'」と宣言する標準的な方法です。
そして、ageのデフォルト値をNoneに設定します。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
ヒント
idもOptionalで定義します。しかし、idについては後で説明します。
このようにして、**SQLModel**に、データの検証時にageは必須ではなく、デフォルト値がNoneであることを伝えます。
そして、SQLデータベースでは、ageのデフォルト値はNULL(PythonのNoneに相当するSQL)であることも伝えます。
そのため、このカラムは「NULL許容」(NULLに設定できます)。
情報
**Pydantic**の観点から、ageは**オプションフィールド**です。
**SQLAlchemy**の観点から、ageは**NULL許容カラム**です。
主キーid¶
では、idフィールドを確認しましょう。これは、主キーです。
そのため、idを**主キー**としてマークする必要があります。
そのためには、sqlmodelの特別なField関数を使用して、引数primary_key=Trueを設定します。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
このようにして、**SQLModel**に、このidフィールド/カラムがテーブルの主キーであることを伝えます。
しかし、SQLデータベース内では、常に必須であり、NULLにはできません。なぜOptionalで宣言する必要があるのでしょうか?
idはデータベースでは必須ですが、データベースによって生成され、コードによって生成されるわけではありません。
そのため、このクラスのインスタンスを作成する際は(次の章で)、idは設定しません。そして、idの値は、データベースに保存されるまでNoneであり、最終的に値を持つようになります。
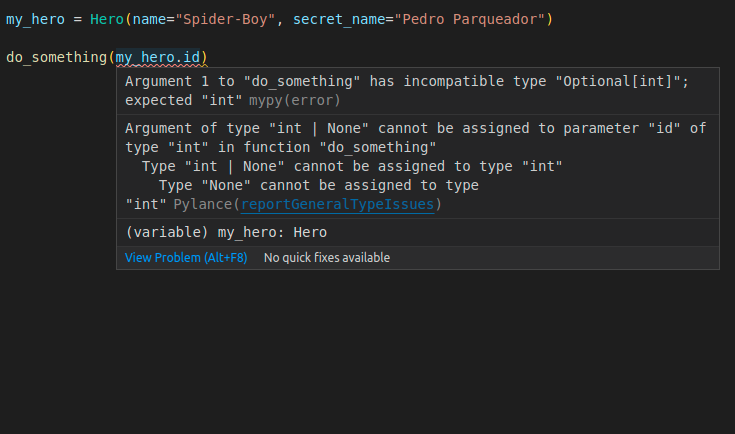
my_hero = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
do_something(my_hero.id) # Oh no! my_hero.id is None! 😱🚨
# Imagine this saves it to the database
somehow_save_in_db(my_hero)
do_something(my_hero.id) # Now my_hero.id has a value generated in DB 🎉
そのため、コード内(データベース内ではない)でidの値がNoneになる可能性があるため、Optionalを使用します。これにより、例えば、まだデータベースに保存しておらず、まだNoneであるオブジェクトのidにアクセスしようとすると、**エディタが支援してくれる**ようになります。
さて、Field()関数でデフォルト値を置き換えているため、Field()の引数default=Noneでidの**実際のデフォルト値**をNoneに設定します。
Field(default=None)
default値を設定しなかった場合、後でこのモデルを使用してデータ検証(Pydanticによって強化されている)を行うときは、intとは別にNoneの値を受け入れますが、そのNone値の渡しが依然として**必須**になります。そして、後でこのモデルを使用する人(おそらく私たち自身)にとって混乱を招くため、**ここでデフォルト値を設定する方が良い**でしょう。
エンジンの作成¶
今度は、SQLAlchemyの**エンジン**を作成する必要があります。
これは、データベースとの通信を処理するオブジェクトです。
サーバーデータベース(PostgreSQLやMySQLなど)を使用している場合、**エンジン**は、そのデータベースへの**ネットワーク接続**を保持します。
**エンジン**の作成は非常に簡単です。使用するデータベースのURLを使用してcreate_engine()を呼び出すだけです。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
通常、アプリケーション全体で単一の**エンジン**オブジェクトを持ち、いたるところで再利用する必要があります。
ヒント
**セッション**と呼ばれる関連するものがもう一つありますが、これは通常、アプリケーションごとに単一のオブジェクトにするべきではありません。
しかし、これについては後で説明します。
エンジンのデータベースURL¶
サポートされている各データベースには、独自のURLタイプがあります。たとえば、**SQLite**の場合は、ファイルパスに続くsqlite:///です。たとえば
sqlite:///database.dbsqlite:///databases/local/application.dbsqlite:///db.sqlite
SQLiteは、すべてメモリ内にある特別なデータベースをサポートしています。そのため非常に高速ですが、注意が必要です。プログラムが終了するとデータベースが削除されます。このメモリ内データベースは、スラッシュを2つ(//)使用し、ファイル名を指定しないことで指定できます。
sqlite://
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
**SQLAlchemy**(そして、**SQLModel**)によってサポートされているすべてのデータベースについて、さらに多くの情報については、SQLAlchemyのドキュメントを参照してください。
エンジンのエコー¶
この例では、echo=Trueという引数も使用しています。
これにより、エンジンが実行するすべてのSQL文が出力され、何が起こっているかを理解するのに役立ちます。
これは特に、学習とデバッグに役立ちます。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
しかし、本番環境では、おそらくecho=Trueを削除する必要があります。
engine = create_engine(sqlite_url)
エンジンに関する技術的な詳細¶
ヒント
以前SQLAlchemyについて知らなかった場合、そしてSQLModelをこれから学習する場合、このセクションはスキップして、下にスクロールしても構いません。
SQLAlchemyのドキュメントで、エンジンについてさらに詳しく読むことができます。
SQLModelは独自のcreate_engine()関数を定義しています。これはSQLAlchemyのcreate_engine()と同じですが、future=Trueを使用することをデフォルトとしている点が異なります(つまり、最新のSQLAlchemy 1.4と将来の2.0のスタイルを使用することを意味します)。
また、SQLModelのcreate_engine()は内部的に型注釈されているため、エディターが自動補完とインラインエラーの検出に役立ちます。
データベースとテーブルの作成¶
これで、データベースとテーブルを作成する準備が整いました。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
ヒント
エンジンを作成しても、database.dbファイルは作成されません。
しかし、SQLModel.metadata.create_all(engine)を実行すると、database.dbファイルが作成され、そのデータベースにheroテーブルが作成されます。
これら両方がこの1つのステップで実行されます。
詳しく見ていきましょう。
SQLModel.metadata.create_all(engine)
SQLModel MetaData¶
SQLModelクラスにはmetadata属性があります。これはMetaDataクラスのインスタンスです。
SQLModelを継承し、table = Trueで設定されたクラスを作成するたびに、このmetadata属性に登録されます。
そのため、最後の行で、SQLModel.metadataにはすでにHeroが登録されています。
create_all()の呼び出し¶
SQLModel.metadataにあるこのMetaDataオブジェクトには、create_all()メソッドがあります。
これはエンジンを受け取り、それを使用してデータベースと、このMetaDataオブジェクトに登録されているすべてのテーブルを作成します。
SQLModel MetaDataの順序が重要¶
これは、SQLModelを継承する新しいモデルクラスを作成するコードの後にSQLModel.metadata.create_all()を呼び出す必要があることも意味します。
例えば、次のようなことを想像してみてください。
- モデルを1つのPythonファイル
models.pyに作成します。 - エンジンオブジェクトをファイル
db.pyに作成します。 - メインアプリを作成し、
app.pyでSQLModel.metadata.create_all()を呼び出します。
SQLModelだけをインポートして、app.pyでSQLModel.metadata.create_all()を呼び出そうとした場合、テーブルは作成されません。
# This wouldn't work! 🚨
from sqlmodel import SQLModel
from .db import engine
SQLModel.metadata.create_all(engine)
これは、SQLModelだけをインポートしても、Pythonはそれを継承するクラス(この例ではHeroクラス)を作成するすべてのコードを実行しないため、SQLModel.metadataはまだ空であるためです。
しかし、SQLModel.metadata.create_all()を呼び出す前にモデルをインポートすれば、機能します。
from sqlmodel import SQLModel
from . import models
from .db import engine
SQLModel.metadata.create_all(engine)
これは、モデルをインポートすることで、PythonがSQLModelを継承するクラスを作成するすべてのコードを実行し、それらをSQLModel.metadataに登録するためです。
別の方法として、db.py内でSQLModelとモデルをインポートすることもできます。
# db.py
from sqlmodel import SQLModel, create_engine
from . import models
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url)
そして、app.pyでdb.pyからSQLModelをインポートし、そこでSQLModel.metadata.create_all()を呼び出します。
# app.py
from .db import engine, SQLModel
SQLModel.metadata.create_all(engine)
db.pyからSQLModelをインポートすることで動作します。なぜなら、SQLModelもdb.pyでインポートされているからです。
そして、この方法は正しく動作し、データベースにテーブルを作成します。なぜなら、db.pyからSQLModelをインポートすることで、Pythonはdb.pyファイル内でSQLModelを継承するクラスを作成するすべてのコード(例えば、Heroクラス)を実行するからです。
マイグレーション¶
この簡単な例と、チュートリアル - ユーザーガイドの大部分では、SQLModel.metadata.create_all()を使用するだけで十分です。
しかし、本番システムでは、データベースを移行するシステムを使用したいと思うでしょう。
これは、例えば、列を追加または削除したり、新しいテーブルを追加したり、型を変更したりする場合に役立ちます。
しかし、マイグレーションについては、後の高度なユーザーガイドで学習します。
プログラムの実行¶
プログラムを実行して、すべてが機能していることを確認しましょう。
まだ行っていない場合は、コードをapp.pyファイルに入れてください。
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
ヒント
実行する前に仮想環境をアクティブ化することを忘れないでください。
Pythonでプログラムを実行します。
// We set echo=True, so this will show the SQL code
$ python app.py
// First, some boilerplate SQL that we are not that interested in
INFO Engine BEGIN (implicit)
INFO Engine PRAGMA main.table_info("hero")
INFO Engine [raw sql] ()
INFO Engine PRAGMA temp.table_info("hero")
INFO Engine [raw sql] ()
INFO Engine
// Finally, the glorious SQL to create the table ✨
CREATE TABLE hero (
id INTEGER,
name VARCHAR NOT NULL,
secret_name VARCHAR NOT NULL,
age INTEGER,
PRIMARY KEY (id)
)
// More SQL boilerplate
INFO Engine [no key 0.00020s] ()
INFO Engine COMMIT
情報
読みやすくするために、上記の出力は少し簡略化しました。
しかし、実際には、次のように表示される代わりに
INFO Engine BEGIN (implicit)
次のような表示になります。
2021-07-25 21:37:39,175 INFO sqlalchemy.engine.Engine BEGIN (implicit)
TEXTまたはVARCHAR¶
前の章の例では、一部の列にTEXTを使用してテーブルを作成しました。
しかし、この出力では、SQLAlchemyが代わりにVARCHARを使用しています。何が起こっているのか見てみましょう。
各SQLデータベースは、サポートする内容にいくつかの違いがあることを思い出してください。
これはその違いの1つです。各データベースは、INTEGERやTEXTなど、特定のデータ型をサポートしています。
一部のデータベースには、特定の用途に特化した特定の型があります。例えば、PostgreSQLとMySQLは、TrueとFalseの値にBOOLEANをサポートしています。SQLiteは、テーブル列を定義する場合でも、ブール値を含むSQLを受け入れますが、内部的には実際にはINTEGERを使用しており、1はTrueを表し、0はFalseを表します。
同様に、文字列を格納するためのいくつかの可能な型があります。SQLiteはTEXT型を使用します。しかし、PostgreSQLやMySQLなどの他のデータベースは、デフォルトでVARCHAR型を使用し、VARCHARは最も一般的なデータ型の1つです。
VARCHARは、variable length character(可変長文字)の略です。
SQLAlchemyは、VARCHARを使用してテーブルを作成するSQL文を生成し、SQLiteがそれらを受け取り、内部的にTEXTに変換します。
これらの2つのデータ型の違いに加えて、MySQLなどのデータベースでは、VARCHAR型の長さを最大値に設定する必要があります。例えば、VARCHAR(255)は文字数を最大255に設定します。
使用するデータベース(MySQLでも)に関係なく、SQLModelの使用をすぐに開始できるようにし、追加の設定なしで、デフォルトではstrフィールドはほとんどのデータベースではVARCHARとして、MySQLではVARCHAR(255)として解釈されます。これにより、同じクラスが追加の労力なしで最も一般的なデータベースと互換性があることがわかります。
ヒント
文字列列の最大長を変更する方法については、後の高度なチュートリアル - ユーザーガイドで学習します。
データベースの検証¶
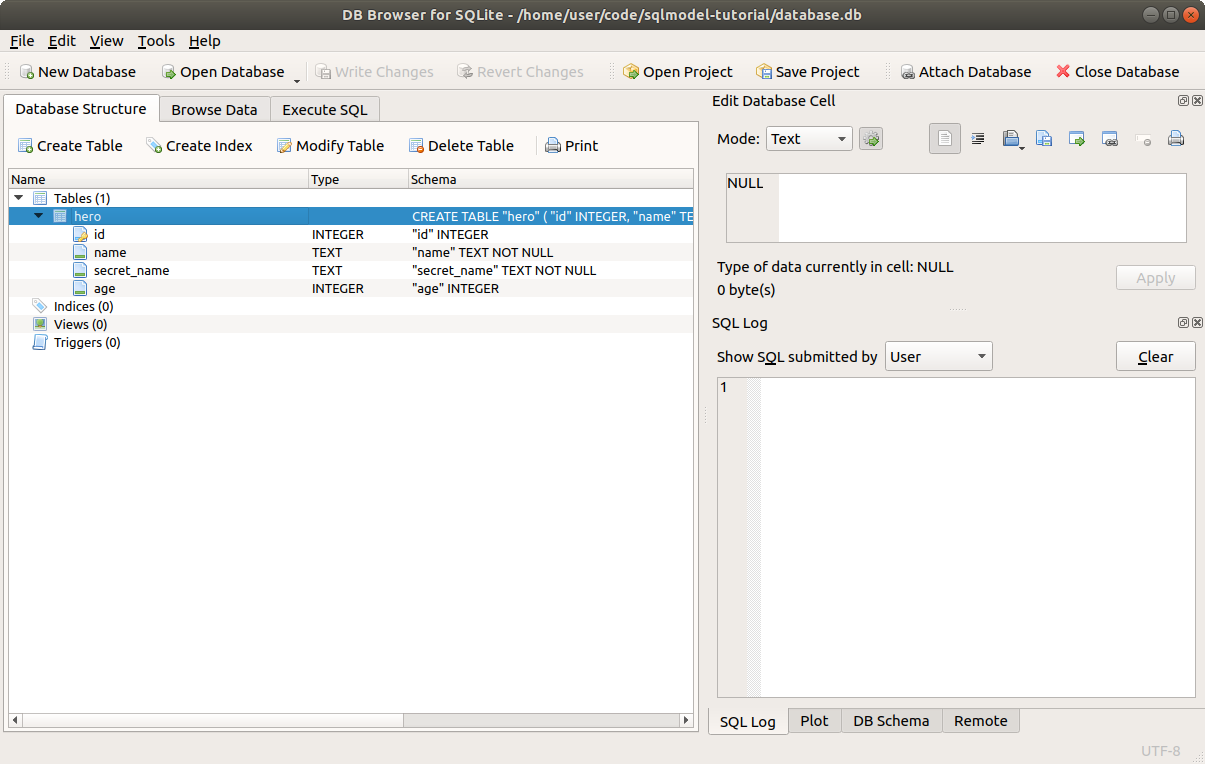
ここで、DB Browser for SQLiteでデータベースを開くと、プログラムが以前と同じようにheroテーブルを作成していることがわかります。🎉
データ作成のリファクタリング¶
次に、後で簡単に再利用、共有、テストできるように、コードを少し再構成しましょう。
データ(データベースとテーブルを含むファイルを作成する)を変更する主な副作用を持つコードを関数に移動しましょう。
この例では、SQLModel.metadata.create_all(engine)だけです。
create_db_and_tables()関数に入れてみましょう。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
# More code here later 👇
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
# More code here later 👇
👀 ファイル全体のプレビュー
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
SQLModel.metadata.create_all(engine)が関数内にない場合、このモジュール(このファイル)から何かを別のモジュールからインポートしようとすると、このモジュールをインポートした他のファイルを実行するたびにデータベースとテーブルを作成しようとします。
そうしたくありません。意図した時だけ実行したいので、関数に入れておきます。関数の呼び出し時だけテーブルが作成され、他の場所でこのモジュールがインポートされたときには作成されないようにするためです。
これで、例えば、それらの副作用なしで、別のファイルでHeroクラスをインポートできるようになります。
ヒント
😅 ネタバレ注意:関数はcreate_db_and_tables()と呼ばれています。なぜなら、将来Hero以外にも他のクラスでテーブルが増えるからです。🚀
データのスクリプトとしての作成¶
app.pyファイルから何かをインポートしたときの副作用を防ぎました。
しかし、それでも、ターミナルから独立したスクリプトとしてPythonで直接呼び出したときに、上記のようにデータベースとテーブルを作成したいと考えています。
ヒント
スクリプトとプログラムという言葉は、互換性があると考えてください。
スクリプトという言葉は、多くの場合、コードを独立して簡単に実行できることを意味します。あるいは、場合によっては、比較的単純なプログラムを指します。
そのため、ifブロックで特別な変数__name__を使用できます。
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str
secret_name: str
age: int | None = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
SQLModel.metadata.create_all(engine)
if __name__ == "__main__":
create_db_and_tables()
__name__ == "__main__"について¶
__name__ == "__main__"の主な目的は、ファイルが次のように呼び出されたときに実行されるコードを持つことです。
$ python app.py
// Something happens here ✨
…しかし、別のファイルがそれをインポートしたときには呼び出されません(例:)。
from app import Hero
ヒント
if __name__ == "__main__":を使用するそのifブロックは、時々「メインブロック」と呼ばれます。
公式名称(Pythonドキュメント内)は「トップレベルスクリプト環境」です。
詳細¶
ファイル名がmyapp.pyだとしましょう。
次のように実行すると
$ python myapp.py
// This will call create_db_and_tables()
…すると、Pythonによって自動的に作成されるファイル内の内部変数`__name__`の値は文字列`"__main__"`になります。
そのため、以下の関数…
if __name__ == "__main__":
create_db_and_tables()
…が実行されます。
そのモジュール(ファイル)をインポートした場合、これは発生しません。
そのため、`importer.py`という別のファイルがあり、以下のような内容の場合…
from myapp import Hero
# Some more code
…その場合、`myapp.py`内の自動変数`__name__`は`"__main__"`という値を持ちません。
そのため、以下の行…
if __name__ == "__main__":
create_db_and_tables()
…は実行されません。
情報
詳細については、公式Pythonドキュメントを参照してください。
最終レビュー¶
これらの変更後、再度実行すると、以前と同じ出力が生成されます。
しかし、これで他のファイルからこのモジュール内のものをインポートできるようになりました。
では、コードを最終的に見てみましょう。
from sqlmodel import Field, SQLModel, create_engine # (2)!
class Hero(SQLModel, table=True): # (3)!
id: int | None = Field(default=None, primary_key=True) # (4)!
name: str # (5)!
secret_name: str # (6)!
age: int | None = None # (7)!
sqlite_file_name = "database.db" # (8)!
sqlite_url = f"sqlite:///{sqlite_file_name}" # (9)!
engine = create_engine(sqlite_url, echo=True) # (10)!
def create_db_and_tables(): # (11)!
SQLModel.metadata.create_all(engine) # (12)!
if __name__ == "__main__": # (13)!
create_db_and_tables() # (14)!
- `typing`から`Optional`をインポートして、`None`になる可能性のあるフィールドを宣言します。
- `sqlmodel`から必要なもの(`Field`、`SQLModel`、`create_engine`)をインポートします。
-
データベースの`hero`テーブルを表す`Hero`モデルクラスを作成します。
また、このクラスを`table=True`でテーブルモデルとしてマークします。
-
`id`フィールドを作成します。
データベースが値を割り当てるまでは`None`になる可能性があるため、`Optional`で注釈を付けます。
これは主キーなので、`Field()`と引数`primary_key=True`を使用します。
-
`name`フィールドを作成します。
必須なので、デフォルト値はなく、`Optional`でもありません。
-
`secret_name`フィールドを作成します。
これも必須です。
-
`age`フィールドを作成します。
必須ではなく、デフォルト値は`None`です。
データベースでは、デフォルト値は`NULL`(`None`のSQL相当)になります。
このフィールドは`None`(データベースでは`NULL`)になる可能性があるため、`Optional`で注釈を付けます。
-
データベースファイルの名前を記述します。
- データベースファイルの名前を使用して、データベースURLを作成します。
-
URLを使用してエンジンを作成します。
まだデータベースは作成されていません。この時点ではファイルもテーブルも作成されていません。作成されるのは、この特定のデータベースとの接続を処理し、SQLite(URLに基づく)を具体的にサポートするエンジンオブジェクトだけです。
-
副作用のあるコードを関数にまとめます。
この例では、テーブルを含むデータベースファイルを作成する1行のみです。
-
`SQLModel.metadata`に自動的に登録されたすべてのテーブルを作成します。
-
メインブロック、または「トップレベルスクリプト環境」を追加します。
そして、以下のようにPythonで直接呼び出されたときに実行されるロジックを追加します。
$ python app.py // Execute all the stuff and show the output…しかし、このモジュールから何かをインポートするとき(例:…)には実行されません。
from app import Hero -
このメインブロックで、データベースファイルとテーブルを作成する関数を呼び出します。
このようにして、以下のように呼び出すと…
$ python app.py // Doing stuff ✨…データベースファイルとテーブルが作成されます。
from typing import Optional # (1)!
from sqlmodel import Field, SQLModel, create_engine # (2)!
class Hero(SQLModel, table=True): # (3)!
id: Optional[int] = Field(default=None, primary_key=True) # (4)!
name: str # (5)!
secret_name: str # (6)!
age: Optional[int] = None # (7)!
sqlite_file_name = "database.db" # (8)!
sqlite_url = f"sqlite:///{sqlite_file_name}" # (9)!
engine = create_engine(sqlite_url, echo=True) # (10)!
def create_db_and_tables(): # (11)!
SQLModel.metadata.create_all(engine) # (12)!
if __name__ == "__main__": # (13)!
create_db_and_tables() # (14)!
- `typing`から`Optional`をインポートして、`None`になる可能性のあるフィールドを宣言します。
- `sqlmodel`から必要なもの(`Field`、`SQLModel`、`create_engine`)をインポートします。
-
データベースの`hero`テーブルを表す`Hero`モデルクラスを作成します。
また、このクラスを`table=True`でテーブルモデルとしてマークします。
-
`id`フィールドを作成します。
データベースが値を割り当てるまでは`None`になる可能性があるため、`Optional`で注釈を付けます。
これは主キーなので、`Field()`と引数`primary_key=True`を使用します。
-
`name`フィールドを作成します。
必須なので、デフォルト値はなく、`Optional`でもありません。
-
`secret_name`フィールドを作成します。
これも必須です。
-
`age`フィールドを作成します。
必須ではなく、デフォルト値は`None`です。
データベースでは、デフォルト値は`NULL`(`None`のSQL相当)になります。
このフィールドは`None`(データベースでは`NULL`)になる可能性があるため、`Optional`で注釈を付けます。
-
データベースファイルの名前を記述します。
- データベースファイルの名前を使用して、データベースURLを作成します。
-
URLを使用してエンジンを作成します。
まだデータベースは作成されていません。この時点ではファイルもテーブルも作成されていません。作成されるのは、この特定のデータベースとの接続を処理し、SQLite(URLに基づく)を具体的にサポートするエンジンオブジェクトだけです。
-
副作用のあるコードを関数にまとめます。
この例では、テーブルを含むデータベースファイルを作成する1行のみです。
-
`SQLModel.metadata`に自動的に登録されたすべてのテーブルを作成します。
-
メインブロック、または「トップレベルスクリプト環境」を追加します。
そして、以下のようにPythonで直接呼び出されたときに実行されるロジックを追加します。
$ python app.py // Execute all the stuff and show the output…しかし、このモジュールから何かをインポートするとき(例:…)には実行されません。
from app import Hero -
このメインブロックで、データベースファイルとテーブルを作成する関数を呼び出します。
このようにして、以下のように呼び出すと…
$ python app.py // Doing stuff ✨…データベースファイルとテーブルが作成されます。
ヒント
コード内の各番号のバブルをクリックして、各行が何をしているかを確認してください。👆
まとめ¶
SQLModelを使用してデータベースのテーブルの構造を定義する方法を学び、SQLModelを使用してデータベースとテーブルを作成しました。
また、コードをリファクタリングして、再利用、共有、および後のテストを容易にしました。
以降の章では、SQLModelがコードからSQLデータベースとのやり取りをどのように支援するかを見ていきます。🤓